





Como periodistas que se ocupan de datos y archivos, encontramos que la información más interesante suele estar oculta en colecciones de documentos grandes, no estructurados e incompletos. Especialmente la información en los contratos públicos: qué compra el gobierno, cuánto dinero se gasta, quiénes son los proveedores.
Para responder a estas preguntas, cuatro compañías de medios colaboraron bajo JournalismAI Collab para crear una plataforma para reporteros que utilizan diversas herramientas y técnicas de aprendizaje automático para comprender y procesar documentos que no están estructurados para obtener información útil. Este sitio terminó siendo «Dawkins».
Concluimos que la acreditación organizacional etiquetada (NER) es útil para identificar fácilmente elementos clave en un conjunto de documentos, como nombres, ubicaciones, marcas o valores monetarios de las personas.
Por eso probamos dos modelos NER para documentos en español: SpaCy y DocumentCloud (que usa el lenguaje natural de Google Cloud) en los documentos de adquisiciones del Ministerio de Defensa publicados en el Boletín Oficial de Argentina.
Seguimos los siguientes pasos para esta estandarización:
- Extracción y modelización de documentos del Boletín Oficial de Argentina.
- Codifique manualmente empresas modelo con Amazon Sagemaker.
- Usar SpaCy para usar el mismo tipo de autenticación empresarial.
- Usar Document Cloud (Google Cloud Natural Language) para usar la autenticación corporativa con un nombre similar.
- Evaluar el desempeño de ambos modelos.
- Analizando errores en ambos modelos.
Extracción y modelización de documentos del Boletín Oficial de Argentina
los Gaceta Oficial de la República Argentina (BORA) El gobierno argentino es el diario oficial que publica sus disposiciones legales y demás funciones gubernamentales desde los poderes legislativo, ejecutivo y judicial.
En esta Gaceta, hay una sección donde casi todas las licitaciones y contratos se publican en documentos inacabados. Nos enfocamos en estos documentos ya que existe un sitio oficial donde los contratos se publican en forma abierta, pero no todos se pueden encontrar.
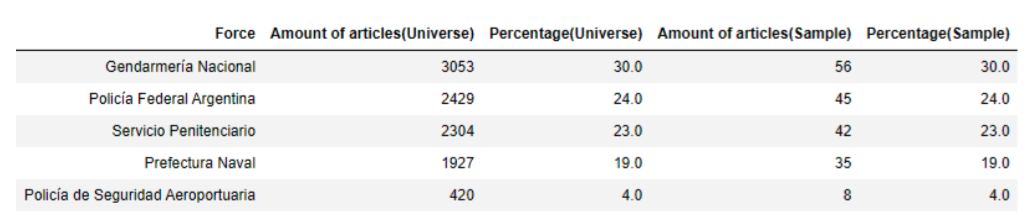
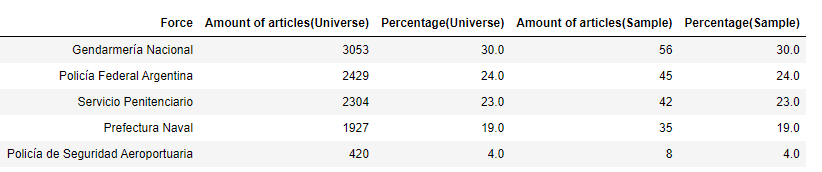
Desde 2014 hasta septiembre de 2021 hemos raspado 10.133 documentos de este Boletín, incluyendo el Ministerio de Defensa y sus cinco fuerzas (Gendarmería Nacional, Policía Federal Argentina, Servicio Penitenciario, Poricudaí Naval y Policudaí Naval, y el Ministerio de Defensa, Naval y Pvt. Contiene información sobre licitaciones, contratos y adquisiciones de
Luego, hicimos un modelo en capas proporcional al tipo de clave con un nivel de confianza del 90% y un margen de error del 6%.
Codificar manualmente los objetos del modelo
Para comparar el rendimiento de los dos modelos NER, el modelo debe identificar qué empresas contiene cada documento y dónde se encuentran. Para este paso, etiquetamos manualmente 186 documentos de la muestra de Amazon Sagemaker, un servicio de AWS que permite al usuario crear y entrenar modelos de aprendizaje automático, con cinco etiquetas como ubicación, organización, evento, personas, etc.
Cuando terminamos, obtenemos el archivo JSON de la herramienta que contiene el ID del documento, las empresas, sus etiquetas y su estado (inicio y finalización).

Uso de SpaCy con el mismo tipo de autenticación empresarial que el nombre indica
Después de la etiqueta manual, usamos Spacey, Una biblioteca gratuita de código abierto para el procesamiento del lenguaje natural en Python. Tiene diferentes pipelines y pesos pre-entrenados descargables para diferentes idiomas. En este caso trabajamos El gasoducto español Spaci 3.0 es pequeño Autorizar empresas en los mismos documentos utilizados en el paso anterior.
Usamos la biblioteca Pandas para leer el csv de muestra y crear la salida.
Muy fácil de implementar y operar:
- Instale la biblioteca Spoxy. Puede encontrar instrucciones sobre cómo hacerlo aquí..
- Seleccione la canalización que desea usar y descargue.
- Importe la biblioteca de Spocy y la biblioteca de Pandas a su cuaderno:

- Lea los datos que desea usar (usando pandas):
- Ejecute el canal de PNL:
- Crear una base de datos con resultados de PNL: Después de ejecutar el pipeline, crearemos una base de datos con el ID del documento, las empresas, sus etiquetas y su estado (inicio y finalización).
- Descargar Dataframe como archivo CSV:



Usar DocumentCloud (Google Cloud Natural Language) para usar la autenticación empresarial con un nombre similar.
Para nuestra otra prueba, usamos la API de Document Cloud para extraer elementos de muestras de documentos BORA. Document Cloud utiliza Google Cloud Natural Language para identificar y extraer empresas de una colección de documentos.
Para consultar la API de DocumentCloud con lenguaje Python, primero debemos instalarlo [python-documentcloud] Biblioteca. Una vez configurado el acceso a DocumentCloud (Usuario – Contraseña – ID del proyecto), repasamos los documentos del proyecto uno a uno y solicitamos el endpoint específico de la API que responde con el contenido de cada documento.
Obtuvimos el archivo JSON de este proceso junto con el ID del documento, empresas, sus etiquetas y estado (inicio y fin).
Evaluar el desempeño de ambos modelos
Para evaluar el rendimiento de los modelos, comparamos las empresas en el etiquetado manual con el espacio de espacio a un lado. Esta comparación se realiza en una configuración de tabla, lo que permite visualizar el rendimiento de un algoritmo llamado Matriz de confusión.
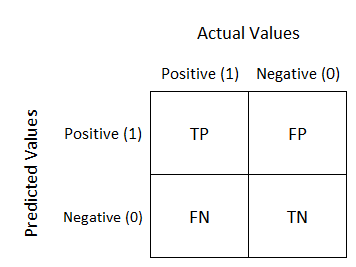
Para cada empresa del mismo documento, calculamos la distancia de Levenshtein (el número que le dice cuán diferentes son las dos cadenas). Para esta tarea, usamos Biblioteca oscura.
Aquellas empresas cuya distancia levenshtein era igual o superior a 70 se consideraron verdaderas positivas. Aquellos que no estaban en la base de datos muestreada y etiquetada manualmente o que tenían una distancia de Levenshtein de menos de 70 se consideraron falsos positivos. Aquellos que no fueron detectados por la muestra en la base de datos etiquetada manualmente o que tuvieran una distancia de Levenshtein de menos de 70 se consideraron falsos negativos.
Luego, para evaluar el desempeño de los modelos monitoreados, calculamos tres métricas comunes: recuperación, precisión y puntaje F1.
Precisión: La proporción de observaciones positivas pronosticadas con precisión y el total de observaciones positivas pronosticadas.
Recordatorio: La proporción de observaciones positivas pronosticadas positivamente con respecto a todas las observaciones de la clase real.
Puntuación F1: Precisión y recuperación de peso medio. Por tanto, esta puntuación tiene en cuenta tanto los falsos positivos como los falsos negativos. Más cerca de 1, el modelo funciona mejor.
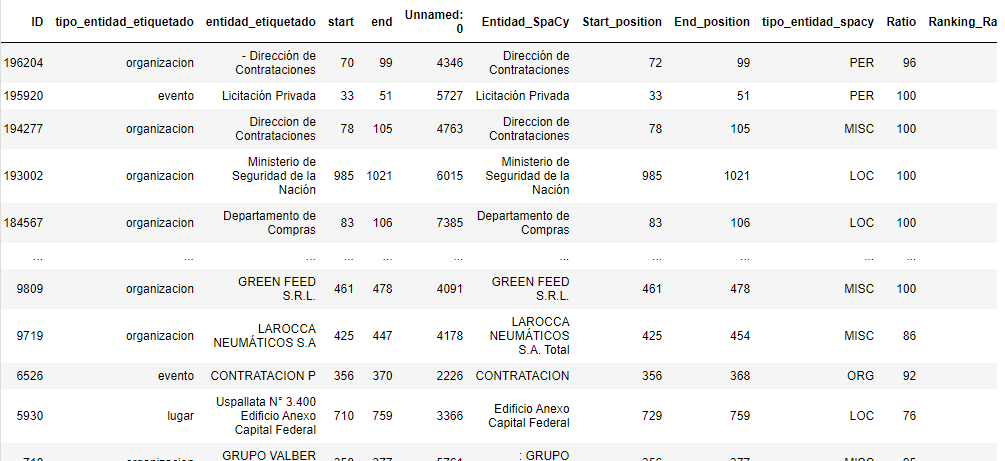
Estos son los resultados iniciales que recibimos para Spaci:
Precisión = 0.014 Recuperación = 0.095 Puntaje F1 = 0.025
Estos son los resultados iniciales de DocumentCloud (API de Google Cloud):
Precisión = 0.044 Recuperación = 0.138 Puntaje F1 = 0.067
Análisis de errores en ambos modelos
En ambos modelos encontramos:
A) Para algunas empresas marcadas por la singularidad humana, las dos soluciones NER las dividen en partes. Por ejemplo, los documentos de «Gendarmería Nacional – Departamento de Compras» tienden a identificar dos empresas, «Gendarmería Nacional» por un lado y «Departamento de Compras» por el otro.
b) Las publicaciones varían según el tipo de organización. Por ejemplo: las fechas y los montos son aprobados por Entity Extractor de Google, pero no por SpaCy. Además, ese tipo de empresas no se consideran en la codificación manual. Por lo tanto, no tomamos en cuenta las fechas ni el dinero al comparar los dos métodos.
c) Comunicaciones oficiales de los discursos de Bora pero no comunicados de prensa. Por lo tanto, estos textos parecen ser oraciones aisladas pegadas en un solo párrafo. Este tipo de textos son más difíciles para los modelos de PNL porque no siguen el borrador general.
Cuando usamos la herramienta de DocumentCloud, no pudimos personalizar el modelo de API de Google para identificar mejor a las empresas en nuestro modelo. Con SpaCy, pudimos utilizar el componente de canalización Gobernante institucional Para ayudar a aumentar la precisión del modelo. Para EntityRuler, hemos creado Diccionario de Empresas Con sus tipos. Estos incluyen los departamentos y provincias de Argentina, los departamentos del Ministerio de Defensa y los tipos de subastas.
Después de la implementación de EntityRuler, agregamos dos cambios más para hacer la autenticación Spaci NTT: el texto dentro del documento eliminó las minúsculas y minúsculas porque este modelo tiende a reconocer muchas palabras grandes no corporativas y no todas tienen un acento. Estos tres cambios ayudaron al modelo y terminamos con la mejor puntuación F1: de 0.025 a 0.078 mencionado anteriormente.
Como se mencionó anteriormente, la puntuación F1 debe estar más cerca de 1 que de 0. Los puntajes finales no son muy prometedores, pero sabemos que el principal problema radica en las empresas que son consideradas una por estándares humanos, pero las muestras resultan ser dobles. Son diferentes.
Esperamos que una mayor investigación u otra técnica de codificación humana nos ayude a comprender mejor el rendimiento de SpaCy y DocumentCloud en este tipo de documentos.
Sin embargo, los modelos de PNL varían en su rendimiento según el tipo de texto que utilizan. Es por eso que alentamos a la comunidad a probarlos en otros tipos de documentos y soluciones.

«Jugador extremo. Aficionado total a Twitter. Analista. Pionero de los zombis. Pensador. Experto en café. Creador. Estudiante».
More Stories
Data Sovereignty in the Cloud Era: Can Latin America Regain Control?
Ver | La marchadora española Laura García-Caro se quedó sin subir al podio tras una celebración anticipada
Los compradores británicos impulsan el sector inmobiliario español « Euro Weekly News